

We're proud to officially introduce the Furiko project - an open-source, Kubernetes-native platform for scheduling, executing and managing ad-hoc and cron jobs. Furiko is able to schedule jobs to be run on a periodic or once-off basis, supports a wide variety of use cases, and is able to scale to millions of executions per day.

The word "furiko" (振り子) means "pendulum" in Japanese.
Logo designed by Duan Weiwei, distributed under CC-BY 4.0.
Building Furiko internally
To provide a bit of background, Furiko was initially developed in 2020 as an internal platform in Shopee. Our goal was to develop the next generation of a Kubernetes-based job platform for our internal users, known internally as Runonce.
At the time, we were still extensively using Rundeck (now known as PagerDuty Process Automation) as our main platform to schedule, execute and manage jobs across the company.
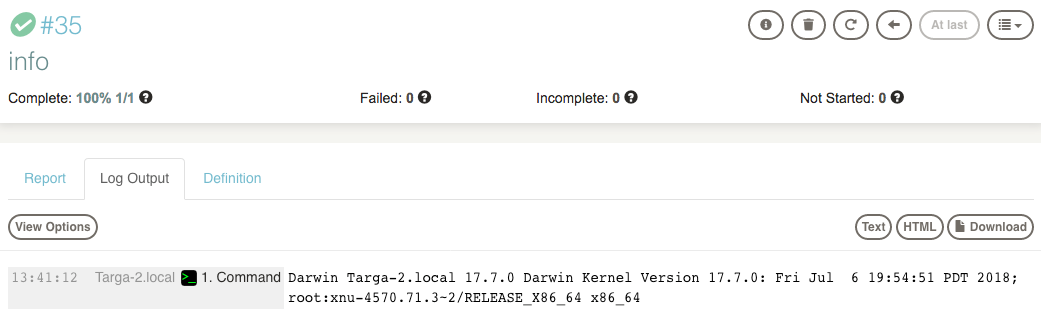
Example job execution in Rundeck. Image source
We were constantly tuning system and JVM parameters, but eventually found ourselves hitting a ceiling with regards to usability, reliability and performance. At one point, our Rundeck instance crashed every other week from running out of memory. This severely affected our users' trust in the platform when their jobs did not run, or when they were stuck indefinitely in an Incomplete state. 😭
We sought to provide the same concepts and similar feature set that our users enjoyed while using Rundeck, but develop it as a Kubernetes-native platform so that we could thoroughly reap the benefits of a controller-based model to significantly improve the reliability and performance of the platform.
Why not just use Job/CronJob?
The biggest question is probably why we decided to rewrite the Job/CronJob controllers in Kubernetes in the first place. For the most part, they could fulfil our requirements, but our initial evaluation found several issues:
- We needed to support timezones in the CronJob (only recently introduced in v1.24).
- We wanted to support custom cron syntaxes, such as the
Hformat found in Jenkins. This would greatly help to load balance a large number of CronJobs in a single cluster. - We wanted to automatically kill the Job if it remains pending for too long, in case the node has issues starting the container, causing the CronJob to get stuck until it is manually resolved.
- We needed to automatically force delete Pods if the node is down and the controller is unable to kill the Job, which may also cause the CronJob to get stuck until the node is recovered.
- We need to ensure that if the CronJob has currently running Jobs, it should not allow a new ad-hoc Job to be run.
- We cannot guarantee that workloads will not be executed more than once, such as from deleting the Pod or being evicted by
kube-controller-manager. This was especially important to prevent double-write issues, such as jobs which perform financial transactions. - At the time, CronJobControllerV2 did not yet exist, and several performance problems riddled the V1 controller. Because it did not use the informer pattern, Jobs were not scheduled timely and the controller could not scale to reconcile thousands of Jobs concurrently.
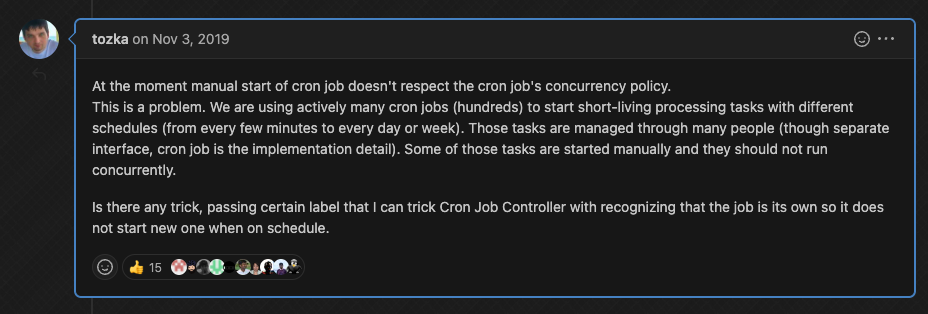
Similar feedback on limitations of the CronJob controller. GitHub
To add on, we were also looking to support features that were already existing in Rundeck in order to migrate our existing customers to the new platform based on Kubernetes. These features included but were not limited to:
- Specify job parameters, allowing us to use a single job as a template.
- Schedule a job for later, rather than executing it immediately.
- Enqueue a bunch of jobs to be run after the previous one finishes, such that they will not run concurrently.
- Support complex job workflows.
- Send notifications when a job starts, finishes, fails, etc.
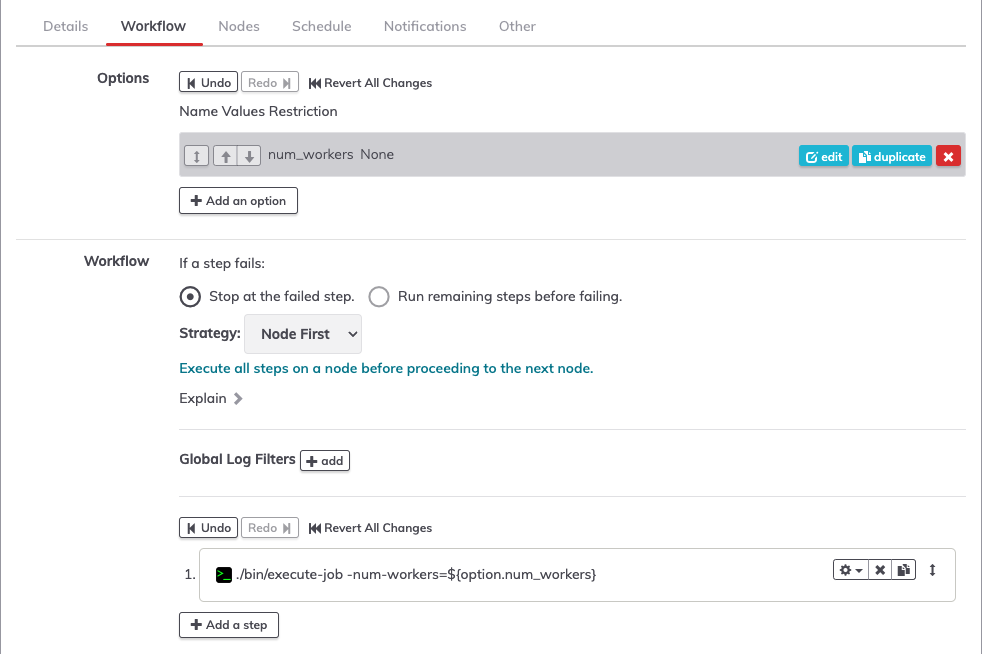
Example of parameterizing a job in Rundeck.
With all of the above in mind, we made a deliberate but painful choice to reinvent the wheel, because the existing controllers in core Kubernetes had no way to support some of these use cases without a complete redesign from scratch. 😓
Designing Furiko
Our initial design introduced the following concepts and ideas, which are roughly inspired from both Kubernetes and Rundeck.
The Job object
A Job is a single job execution, much like the K8s equivalent. If a JobConfig is scheduled to run every 3 hours, a new Job will be created every 3 hours.
The Job object should support features present in K8s, such as parallelism and retry limits. In addition, we also implemented additional features, such as retries using separate Pods, pending timeouts, etc.
Users should not be interacting with the Job object directly most of the time, but instead interact directly with its parent, the JobConfig.
The JobConfig object
A JobConfig (roughly equivalent CronJob in K8s) is a single configuration (or template) for how jobs should be executed.
The JobConfig includes configuration such as automatic scheduling, concurrency handling, job options, and so on.
The difference from CronJob is that all Jobs should be created via its parent JobConfig. By having this assumption, we can track and observe the status of all Jobs for a single JobConfig. In addition, this also provides better user experience since we can now validate and add default parameters when running a Job manually.
JobQueueController
The JobQueueController is responsible for admitting a Job to be started, based on some concurrency or scheduling constraints. It is responsible for the following:
- If the JobConfig is using the
Forbidconcurrency policy, it will not admit a Job when other Jobs are not yet finished. - If the Job is not due to be started (using
startAfter), it will not yet be admitted. - Ensuring FIFO ordering of Jobs to be admitted based on their creation time (assuming no other constraints apply).
This design allows us to move closer towards the user experience that our users enjoyed on Rundeck, while providing the reliability guarantees that allow our users to place trust in running millions of workloads a day in the company.
Sharing Furiko with the world
Fast forward two years later, we were thrilled to have been receiving positive feedback for our internal Runonce platform. We were running millions of executions per day across multiple Kubernetes clusters, and >99.999% on-time scheduling rate (i.e. almost no jobs were detected as overdue via monitoring).
At the same time, we found that there was no comprehensive, open-source, Kubernetes-native cron job platform available yet. As such, we decided to work on open-sourcing Furiko with the rest of the community! 🥳
Although core Kubernetes has made significant strides with regards to the CronJob controller recently (such as CronJobControllerV2 and timeZone support as of v1.24), we still found significant gaps that were not completely addressed. Additionally, we also know that existing tools such as Argo Workflows have similar functionality, but we believe that Furiko may be better positioned to focus on time-based scheduling of jobs on a massive scale.
Although initially developed as an internal platform inside of the company, Furiko is and will always be 100% open source. There are several features that are currently only available in our internal Runonce platform, but we remain hard at work to port over features or ideas from our internal version where appropriate. We also have started working on a community-maintained roadmap for Furiko, which can be found here.
We are still currently very early in our development of Furiko, and we welcome all contributions big or small. To find out more, check out our Contribution Guide.
Try it out
Check out Furiko on GitHub, or the installation guide to get started on a Kubernetes cluster in less than a minute.
To view the full list of features of Furiko, check out the Features page.
Let us know what you think! We are open to questions and feature requests over at our GitHub Discussions page, or you can simply open an issue on our project on GitHub.